

Jak komputer przechowuje tekst?
W poprzednich postach mówiliśmy o zmiennych i różnych operacjach matematycznych jakie możemy na nich wykonywać. Operowaliśmy na liczbach. Dziś coś bardziej w stronę języka polskiego. Zobaczymy w jaki sposób w zmiennych przechowywać tekst.
W poprzednich postach wyobrażaliśmy sobie zmienne jako przegródki w pamięci RAM, w których trzymamy nasze dane. Do tej pory tymi danymi były liczby. Komputer jest maszyną, która wewnętrznie operuje wyłącznie na liczbach. Wyobraźmy sobie, że bierzemy specjalną lupę i patrzymy na pamięć RAM w komputerze. W powiększeniu widzimy pewien kawałek pamięci i jeżeli przyjrzymy się dokładnie to zobaczymy nieprzerwany ciąg cyfr 0 i 1. Są to “bity“. Bit to najmniejsza cząstka informacji dostępna dla komputera. Takich pojedynczych komórek (bitów), jest bardzo dużo i trudno nimi operować.

Dlatego też wymyślono trochę większą jednostkę: “bajt”. Jest to 8 bitów. Bajt piszemy przez duże “B”, a bit jako małe “b”. Różnica to dokładnie 8x, czyli na przykład 3 bajty to 24 bity. Łatwiej było zajmować się bajtami niż bitami, których jest 8x więcej. Ale z czasem i bajt okazał się zbyt małą jednostką, dlatego wprowadzono zasadę mnożników, jak w matematyce. Mamy na przykład metr i kilometr. Przedrostek “kilo” oznacza 1000x więcej. Z bajtami jest bardzo podobnie, z tą różnicą, że 1 kilobajt (kB) to 1024 bajty. Także mamy kB, potem MB (megabajt), GB (gigabajt), TB (terabajt) i tak dalej. Należy zapamiętać, że mnożymy razy 1024.
Wynika to z systemu dwójkowego, którym posługujemy się w informatyce. 1024 to 2 do potęgi 10.
Wracając do pamięci i zmiennych zastanówmy się jak wygląda nasza przegródka, w której trzymamy zmienną typu całkowitego int (ang. Integer). Jak pamiętamy z posta Zmienne w języku Java ma ona 4 bajty. Teraz już wiemy, że oznacza to, że w naszej przegródce zmieszczą się 32 cyfry (4 x 8 = 32). Cyfrą jest jeden bit, czyli 0 lub 1. Jak w takim razie przechowywać tam duże liczby, przecież zapisywaliśmy tam chociażby liczbę 100. Jest to możliwe dzięki systemowi dwójkowemu. Otóż w informatyce dużo łatwiej jest (szczególnie dla komputera) operować na wartościach 0 i 1. To człowiek wymyślił, że każdą liczbę możemy zapisać na wiele różnych sposobów. Na co dzień posługujemy się systemem dziesiętnym, i jego właśnie uczymy się w szkole podstawowej.
Informatyk powinien znać także inne systemy, w szczególności system dwójkowy i szesnastkowy. A tak na prawdę wystarczy znajomość sposobu zamiany z jednego systemu na drugi.
Dlaczego system, który znamy ze szkoły podstawowej nazywa się dziesiętnym? Chodzi o to, że w tym systemie mamy do dyspozycji dokładnie 10 cyfr: 1, 2, 3, 4, 5, 6, 7, 8, 9 i 0. Każdą liczbę możemy przedstawić za pomocą kombinacji tych 10 cyfr. I idąc po kolei, dodając jeden, gdy skończą nam się cyfry (czyli dojdziemy do 9), to w to miejsce wpisujemy 0 i dodajemy z lewej strony 1. Tak jakbyśmy przechodzili na kolejny poziom. I znowu liczymy od 0 do 9. Zwiększamy cyfrę najbardziej z prawej strony. I gdy dojdziemy do 9 (do ostatniej cyfry jaką mamy do dyspozycji) znowu wpisujemy tam 0 i zwiększamy o 1 cyfrę na lewo. Czyli po 19 mamy 20 (9 zmieniła się w 0 a 1 w 2). I tak dalej. A gdy dojdziemy do 99, znowu wchodzimy na wyższy poziom. Zamieniamy od prawej strony 9 na 0, potem musimy zwiększyć cyfrę po lewej. Też 9, czyli też zmieniamy na 0 i dodajemy 1 z lewej strony. Czyli 99 staje się 100.
W systemie dwójkowym mamy do dyspozycji tylko 2 cyfry: 0 i 1. Ale sama reguła jest identyczna (jest taka sama dla każdego systemu tego typu). Także zaczynając od 0, dodajemy 1. Mamy 1. Teraz znowu zwiększamy, ale skończyły nam się cyfry, więc wchodzimy na wyższy poziom. 1 staje się 0 i dopisujemy 1 z lewej strony. I w systemie dwójkowym po 1 jest 10 🙂 Brzmi to bardzo dziwnie za pierwszym razem. Także jeszcze raz powtórzę, mamy do dyspozycji tylko 2 cyfry. Kolejną liczbą jest 11 (bo zwiększamy cyfrę najbardziej z prawej strony). A po kolejnym dodaniu 1 mamy 100 (obie jedynki zamieniają się na 0 i dopisujemy 1 z lewej strony). Mam nadzieję, że poniższy przykład rozjaśni trochę system dwójkowy.
| Liczba dziesiętna | Liczba dwójkowa | Potęgi cyfry 2 |
|---|---|---|
| 0 | 0 | |
| 1 | 1 | 2 ^ 0 |
| 2 | 10 | 2 ^ 1 |
| 3 | 11 | |
| 4 | 100 | 2 ^ 2 |
| 5 | 101 | |
| 6 | 110 | |
| 7 | 111 | |
| 8 | 1000 | 2 ^ 3 |
| 9 | 1001 | |
| 10 | 1010 | |
| … | … | |
| 128 | 10000000 | 2 ^ 7 |
| 256 | 100000000 | 2 ^ 8 |
| 512 | 1000000000 | 2 ^ 9 |
| 1024 | 10000000000 | 2 ^ 10 |
Możemy również zauważyć ciekawą właściwość takich systemów liczbowych. Otóż jeśli weźmiemy podstawę systemu (na przykład cyfrę 2) to aby podnieść ją do którejś potęgi (na przykład do 7) zapisujemy wynik jako jedynkę i siedem zer. Dla systemu dziesiętnego jest podobnie, bo przecież 10 do potęgi 3 to jedynka i trzy zera (1000) 😉
Zasada dodawania jest bardzo prosta. Znając ją możemy w ten sam sposób tworzyć inne różne systemy, na przykład szestnastkowy lub trójkowy. Najprzydatniejszym dla nas będzie dwójkowy i szestnastkowy.
W systemie Windows jest kalkulator, który posiada opcję konwersji pomiędzy systemami. Uruchom go teraz i znajdź tryb “Programisty” (u mnie znajduje się w “Widok” > “Programisty”). Po wpisaniu jakiejś liczby możemy zmienić system w jakim jest ona reprezentowana. Wpisz liczbę dziesiętną i naciśnij “Bin”. Zobaczysz tę liczbę w systemie dwójkowym (od angielskiego słowa Binary czyli właśnie dwójkowy).
Znowu wracając do naszej zmiennej całkowitej równej 100. W przegródce, możemy sobie teraz wyobrazić bardzo dużo innych małych przegródek, które trzymają poszczególne bity w systemie dwójkowym. Znajduje się więc tam: 1100100. Czyli liczbę 100 możemy zapisać za pomocą 7 bitów. Przyjmijmy, że pozostałe bity w naszej przegródce są zerami, czyli nasza przegródka wygląda tak: 00000000000000000000000001100100. Być może pamiętasz, jak wspomniałem że należy dobierać typ zmiennej (rozmiar naszej przegródki) do wartości, jakie będą się tam znajdować. Właśnie dlatego, że w wielu przypadkach będziemy mieli nieużywane bity, które moglibyśmy wykorzystać na inne zmienne.
Dobrze, wiemy już jak komputer w pamięci przechowuje liczby. Jak w takim razie przechowuje tekst, skoro operuje tylko na dwóch cyfrach? Wszystko to stało się możliwe dzięki pewnej umowie. Dawno temu informatycy umówili się, że będą stosować pewien standard i przypisali poszczególnym literom wartości liczbowe. Każda litera z alfabetu angielskiego (czyli bez polskich znaków) dostała swój odpowiednik liczbowy. I tak na przykład litera “A” to liczba “65” a litera “a” to “97” (zwróć uwagę, że ważna jest wielkość litery). Co ciekawe cyfry również otrzymały swój odpowiednik. Na przykład “0” to “48”. Dodatkowo swoje odpowiedniki otrzymały znaki specjalne takie jak spacja, czy enter (przejście do nowej linii). Zdjęcie pochodzi z artykułu na Wikipedii, gdzie możesz znaleźć pełną tabelę ASCII.
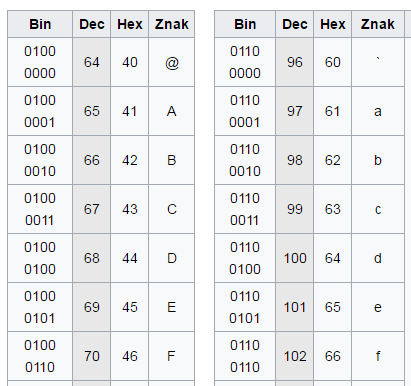
Przykład kodów liter w standardzie ASCII. Źródło: Wikipedia.
Ten standard jest jednak niewystarczający i można w nim przedstawić tylko 127 znaków (na 7 bitach). Dlatego też powstały inne standardy rozszerzające ten podstawowy. W tym również wiele standardów polskich znaków z ogonkami (a także język chiński czy arabski z ich bardzo egzotycznymi symbolami).
Najbardziej popularnym standardem kodowania, w którym możemy zapisać też polskie litery to UTF8 oraz ISO 8859-2 (zwany też Latin2 albo “środkowoeuropejski”). Standard UTF8 jest powszechnie stosowany na stronach internetowych i jeśli będziesz mieć wybór jakie kodowanie zastosować, to najbezpieczniej jest wybrać właśnie UTF8.
A jak w takim razie wyglądają polskie znaki w UTF8? Poniżej znajduje się tabelka, w której widzimy zapis polskich znaków w systemie dziesiętnym, szesnastkowym oraz dwójkowym.
| Znak | System dziesiętny | System szesnastkowy | System dwójkowy |
|---|---|---|---|
| ą | 50309 | C485 | 1100010010000101 |
| ć | 50311 | C487 | 1100010010000111 |
| ę | 50329 | C499 | 1100010010011001 |
| ł | 50562 | C582 | 1100010110000010 |
| ń | 50564 | C584 | 1100010110000100 |
| ó | 50099 | C3B3 | 1100001110110011 |
| ś | 50587 | C59B | 1100010110011011 |
| ź | 50618 | C5BA | 1100010110111010 |
| ż | 50620 | C5BC | 1100010110111100 |
| Ą | 50308 | C484 | 1100010010000100 |
| Ć | 50310 | C486 | 1100010010000110 |
| Ę | 50328 | C498 | 1100010010011000 |
| Ł | 50561 | C581 | 1100010110000001 |
| Ń | 50563 | C583 | 1100010110000011 |
| Ó | 50067 | C393 | 1100001110010011 |
| Ś | 50586 | C59A | 1100010110011010 |
| Ź | 50617 | C5B9 | 1100010110111001 |
| Ż | 50619 | C5BB | 1100010110111011 |
Jak widzisz wszystko zależy od pewnej “umowy”, standardu i bez wiedzy o tym jak programista chce traktować dane, dla komputera liczba dziesiętna 50309 oraz polska litera “ą” to identyczny ciąg zer i jedynek. System operacyjny jest na tyle inteligenty, że wie jak traktować te dane, dzięki typom zmiennych jakie określa programista dla danej przegródki.
A co się stanie jeśli źle określimy kodowanie znaków? To znaczy ktoś zapisał tekst w jednym kodowaniu a ktoś inny odczytując go przyjmuje inne? W zależności od konkretnego przypadku zostaną wyświetlone różne dziwne znaki. Być może gdzieś na stronach internetowych widziałaś tak zwane “krzaki” czy “kwardaciki”. To właśnie błędy w kodowaniu, gdy to źródłowe różni się od tego docelowego. Na poniższym obrazku widać stronę www.onet.pl w przeglądarce Internet Explorer gdy zmieniłem domyślne kodowanie na te używane dla języka chińskiego.

Wracając jednak do naszych zmienny tekstowych, w poniższym kodzie w języku Java widzimy kilka zmiennych typu tekstowego (od angielskiego słowa “String”). Tworzy się je dokładnie tak samo jak zmienne typu liczbowego. W linijkach 4 i 5 przypisujemy im konkretne wartości, które później wyświetlamy na ekran.

Widzimy, że możemy przeprowadzać operacje na zmiennych tekstowych. Jednak nie wszystkie znane nam matematyczne operacje są dozwolone. Bo o ile dodawanie dwóch tekstów jest intuicyjne (czyli chcemy je ze sobą złączyć) to już odejmowanie czy mnożenie niekoniecznie 🙂 W linijce 7 wypisujemy na ekran połączenie dwóch tekstów, czyli z dwóch zmiennych tekstowych powstaje trzecia, która jest ich połączeniem. Takie dodawanie nazywa się konkatenacją (ang. concatenate). W niektórych językach programowania możliwe są również inne operacje, jak np. mnożenie przez liczbę. Na poniższym programie w języku Python wyświetlamy słowo “Droga ” trzy razy (tyle jakiego mnożnika użyliśmy). W języku Java natomiast próba mnożenia tekstu przez liczbę skończyłaby się błędem kompilacji.

A ile w pamięci zajmuje nasza przegródka ze zmienną typu tekstowego? Nie jest to stała wartość jak na przykład 4 bajty dla typu całkowitego. Wielkość zmiennej tekstowej jest dynamiczna, zależy od długości danego tekstu. To tak, jakby przegródka była z gumy i sama dostosowywała swój rozmiar w zależności od potrzeb.
Bo tak na prawdę wszystko w pamięci komputera jest albo zerem albo jedynką i od naszej interpretacji zależy jak te dane zostaną użyte. Zapamiętaj, że istnieje dużo standardów kodowania 0 i 1. Zarówno jeśli chodzi o liczby jak i o tekst. Dla liczb mamy na przykład system dziesiętny czy dwójkowy, a dla tekstu mamy kodowanie UTF8 czy Latin2. Należy pamiętać o tym pisząc programy, żeby czasami nie wy♠wietla♡y nam si♢ r♣♤ne dziwne znaczki 😉










Trackbacks & Pingbacks
[…] Dla chętnych: jeżeli zastanawiasz sie, gdzie podziały się polskie literki i czym jest to <C5> to zapraszam do posta: Jak komputer przechowuje tekst? […]
Leave a Reply
Want to join the discussion?Feel free to contribute!