
Podstawy Gita.
Git to “darmowy i publiczny rozproszony system kontroli wersji” (https://git-scm.com/). Służy do śledzenia zmian w kodzie w projekach programistycznych. W tym poście poznamy podstawy pracy z tym narzędziem.
O systemach kontroli wersji (VCS) pisałem w poście Jak śledzić zmiany w kodzie, część 1. Zachęcam do jego przeczytania, aby poznać ideę systemów VCS. Dla przypomnienia, systemy kontroli wersji pozwalają przeglądać historię zmian w projekcie (kto, kiedy, po co i jakie zmiany wprowadził), przełączać się pomiędzy starszymi / nowszymi wersjami naszego kodu. Dzięki temu programiści mają pewność, że w każdej chwili szybko mogą odtworzyć dokładnie tę wersję kodu, którą potrzebują.
Jest wiele takich systemów (programów). Git charakteryzuje to, że jest rozproszony, czyli nie ma potrzeby posiadania jednego, centralnego serwera. Każdy z programistów korzystających z Gita posiada pełną historię zmian dokonanych przez innych.
Dzięki temu, że Git jest rozproszony, programiści mogą pracować offline i udostępniać innym swoje zmiany jak tylko znajdą darmowe WIFI na swoim “home-office” 😛
Na chwilę obecną znajomość Gita jest jednym z wymagań stawianych kandydatom o pracę nawet na stanowisko Juniora.
Czym właściwie jest Git?
Poza tym, że jest to system, to tak naprawdę Git jest zwykłym programem komputerowym. Można go pobrać ze strony https://git-scm.com/downloads na systemy Windows / Linux / Mac. Po zainstalowaniu mamy tak zwanego klienta Git, czyli programik, dzięki któremu będziemy pracować z Gitem.
Podstawowe pojęcia
Większość pojęć posiada swoje odpowiedniki w komendach, które wydajemy programowi klienta Git.
Repozytorium
Jest to główne pojęcie we wszystkich systemach kontroli wersji. Najprościej rzecz ujmując jest to nasz kod. Cały kod projektu (wszystkie pliki, katalogi, obrazki, itp.) wrzucony w taki wirtualny pojemnik.
Dodatkowo, oprócz kodu, Repozytorium zawiera całą historię zmian. W ukrytym katalogu o nazwie .git w naszym Repozytorium znajduje się dużo informacji, w tym właśnie cała historia. Historia składa się z poszczególnych wersji naszego kodu. Każda wersja zawiera listę zmian w stosunku do poprzedniej wersji. Taka lista zmian nazywa się Commit.
Commit
Edytując nasz projekt i dodając zmiany w kodzie zmieniamy poszczególne pliki. Wszystkie te zmiany możemy ze sobą połączyć w jeden Commit. Czyli oznajmiamy systemowi Git: te wszystkie zmiany na plikach chcę traktować jako nową wersję, jako całość.
Branch (gałęź)
Lista następujących po sobie Commitów tworzy historię zmian. Przeważnie takie zamiany przeprowadza się w jednej gałęzi. Gałęzie możemy trakować jako osobne logiczne odosobnione od siebie zmiany.
Jeżeli wyobrazimy sobie pierwszy Commit jako kropkę (niech będzie korzeniem drzewa), potem każdy kolejny Commit w naszym drzewie tworzy historię zmian. Jeżeli w danym momencie chcemy wprowadzić dwie różne zmiany to tworzymy takie rozgałęzienie i nasza historia ma dwie równoległe gałęzie. Równolegle dodajemy nowe rzeczy do naszego kodu. Programiści pracujący na jednym Branchu (gałęzi) nie przeszkadzają tym pracującym nad drugą gałęzią.
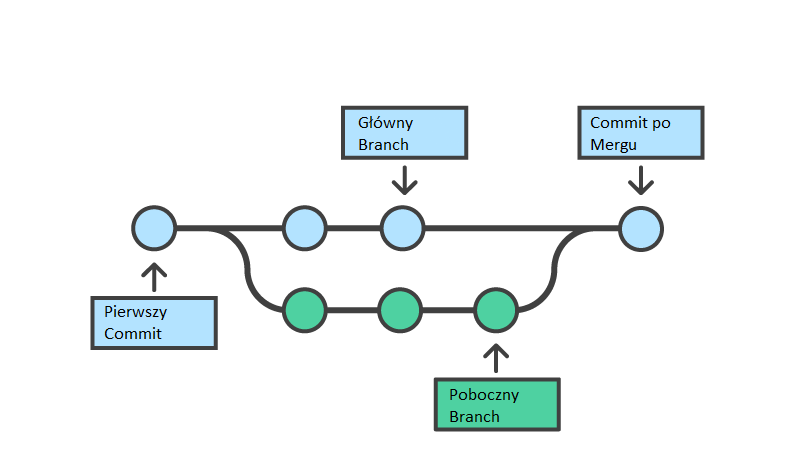
Głównym Branchem nazwiemy tę gałąź, która jest najważniejsza. Zwykle po prostu wybieramy ją i nazywamy na przykład “master” albo “develop”.
Mergowanie
Mając dwie (lub więcej) gałęzi zmian w naszym kodzie, przychodzi czas żeby te zmiany ze sobą połączyć. Wtedy nastęuje proces Mergowania. Czyli z dwóch gałęzi robimy jedną. Jeżeli zmiany wprowadzane były w oddzielnych plikach to wszystko przechodzi bez problemu, uznajemy że te wszystkie pliki i zmiany w nich trafiają do końcowej wersji.
Jeżeli w dwóch Branchach zmiany wprowadzane były w tym samym pliku, to może wystąpić konflikt (Conflict) i należy go rozwiązać. Polega to na tym, że programista decyduje czy zmiana A jest ważniejsz niż zmiana B, czy obie trafiają do końcowej wersji, czy tylko jedna z nich, a może lekko zmieniona wersja A+B. Rozwiązywanie konfliktów wymaga pewnej wprawy, ale nie jest trudne.
Jak zacząć pracować z Gitem?
Po instalacji klienta Gita mamy do dyspozycji kilka poleceń. Nie każdy lubi pracować w linii poleceń, dlatego też powstały graficzne klienty Gita. Ja osobiście używam programu SourceTree (link). Lista takich programów dostępna jest na przykład tutaj: link.
Dobrze jest nauczyć się tych poleceń i popracować trochę w linii poleceń. Dzięki temu lepiej poznamy specyfikę Gita. Mimo że linia poleceń jest mało przyjemna w odbiorze (głównie przez czarno biały wygląd) to nie ma się co jej bać. Często bardzo ułatwia niektóre zadania. I prestiż programistyczny rośnie 🙂
Na początku więc uruchamiamy linię poleceń. Najszybiej poprzez naciśnięcie kombinacji klawiszy Win+R. Pojawi się okienko, dzięki któremu możemu w systemie Windows uruchamiać różne rzeczy. Wpisujemy tam cmd i naciśkamy Enter.
Pojawi się czarno-białe okienko. Po wpisaniu polecenia git i naciśnięciu klawisza Enter pojawi się opis polecenia Git oraz lista dostępnych opcji dla tego polecenia. Ogólnie praktycznie każde z poleceń ma listę opcji, którymi sterujemy co ono zrobi.
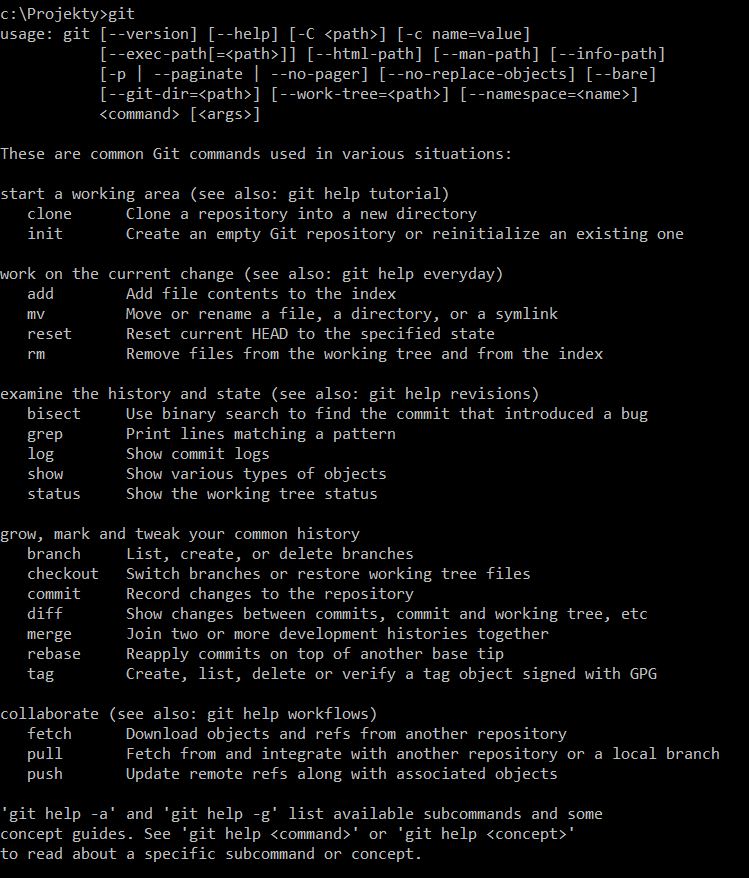
I tak w przypadku Gita najważniejsze opcje to:
INIT
Tworzy repozytorium Gita w danym katalogu. Czyli przechodzimy do katalogu z naszym projektem, wpisujemy git init i od tego momentu, system Git śledzi zmiany w naszych plikach.
Dla chętnych, to polecenie dodaje ukryty katalog .git w którym przechowuje swoje pliki i informacje o repozytorium.

CLONE
Tworzy kopię innego repozytorium, do którego mamy dostęp. Jeżeli ktoś ma jakiś projekt i chce Ci go udostępnić to wpisując git clone <adres_repozytorium> kopiujesz go lokalnie. Masz kopię pełnej historii jego repozytorium, ze wszystkimi commitami, całą historię.

ADD
Ciekawa opcja, która dodaje plik ze zmianami do naszego Commita. To znaczy żeby zapisać listę zmian w historii należy wykonać Commit, ale żeby dodać zmiany do Commita należy wykonać opcję Add. Czyli tak jakby przygotowujemy Commita. Decydujemy, które pliki chcemy zapisać w danej wersji.
Nie wszystkie pliki, które edytujemy, muszą być dodane do Commita. Możemy sami o tym zdecydować.
COMMIT
Gdy już jesteśmy gotowi, zdecydowaliśmy które pliki będą stanowiły daną wersję, akceptujemy ją komendą Commit. Dodatkowo powinnismy wpisać komentarz, który dokładnie opisze co zostało zrobione.
Koniecznie zawsze wpisujcie dobre komentarze. Nie jest to łatwe. Z doświadczenia powiem, że nawet programiści z dużym stażem czasem mają problem z poprawnym opisaniem wprowadzonych zmian.
STATUS
Pokazuje jaki jest status naszego Repozytorium. Widzimy, które pliki zostały zmienone, które już dodaliśmy do następnego Commita, a które jeszce nie są śledzone.
LOG
Przeglądamy historię zmian. Możemy podejrzeć kto, kiedy i jaką zmianę wprowadził. Zostają wyświetlane komentarze do Commita, dlatego ważne jest, aby dobrze określały wprowadzone zmiany.
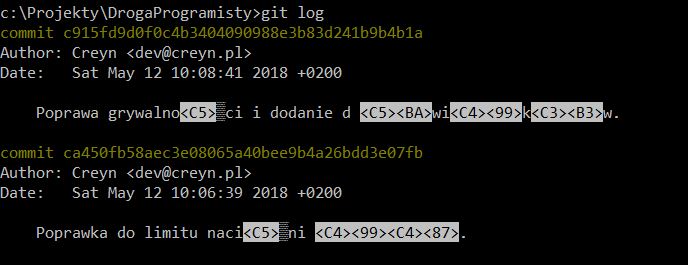
Dla chętnych: jeżeli zastanawiasz sie, gdzie podziały się polskie literki i czym jest to <C5> to zapraszam do posta: Jak komputer przechowuje tekst?
BRANCH
Pokazuje listę gałęzi, które mamy w naszym Repozytorium. Oznacza też tę gałąź na której obecnie pracujemy.
Standardowo główna gałęź na której pracujemy nazywa się master.
Jednocześnie możemy pracować na jednej gałęzi, ale możemy przełączać się pomiędzy nimi. Wtedy odpowiednie pliki są zmieniane i zmiany zostają automatycznie naniesione.

CHECKOUT
Ta komenda umożliwia przełączanie się pomiędzy gałęziami (Branchami). Jeżeli mamy jakieś niezacommitowane zmiany, to zostaną one przeniesione na Branch, na który się przełączamy.
MERGE
Dzięki tej komendzie możemy łączyć ze sobą zmiany wprowadzone w dwoch różnych gałęziach. Możemy sobie to wyobrazić jako skopiowanie zmian z innego Brancha do Commita, który będzie dodany na naszym obecnym Branchu.
PULL
Pobieramy zmiany ze zdalnego Repozytorium, taką kopię kodu, nad którą pracuje nasz kolega. On wprowadza zmiany po swojej stronie, Commituje je do swojej historii. Żeby pobrać je (skopiować) do naszej lokalnej kopii używamy właśnie komendy Pull.
PUSH
To taka odwrotność komendy Pull. Wysyła nasze lokalne zmiany do zdalnego Repozytorium.
Na koniec
Powyżej były screeny z wykonania koment Git z linii poleceń. Poniżej screen z tego samego Repozytorium. Ale tym razem z programu SourceTree. Jest to darmowy klient Git, który bardzo ułatwia pracę z systemami kontroli wersji.

I to z tyle. Są to najważniejsze komendy systemu Git. Dzięki nim możemy pracować nad naszymi projektami i zarządzać historią zmian. Oprócz nich dostępnych jest dużo innych. Dodatkowo te powyższe mają wiele opcji działania. Nie wszystkie jednak się przydają.
W codziennej pracy używa się tylko kilku poleceń Git. Dziś poznaliśmy je w teorii, w przyszłości użyjemy poleceń Git w praktyce.










Trackbacks & Pingbacks
[…] Podstawy GITa. […]
Leave a Reply
Want to join the discussion?Feel free to contribute!